Retail Intelligence Pipeline
Pipeline end-to-end: Python ingesta un dataset de retail en Supabase, dbt construye un star schema con 52 tests automáticos, y Streamlit publica el análisis en producción.
Pipeline completo en producción: ingesta → limpieza → star schema → dashboard
52/52 tests dbt — integridad de datos garantizada en cada capa
Pivote analítico: sin datos de ventas, el análisis se reenfocó en estrategia de góndola
Resumen ejecutivo
Contexto de negocio
Dataset de Blinkit (convenience retail, India) con 1,559 productos en 10 tiendas. El archivo descargado era el test set de Kaggle: sin datos de ventas. En lugar de cambiar el dataset, se reformuló la pregunta: ¿qué tan bien posicionado está el catálogo en cada tipo de tienda?
Mi rol
Construí el pipeline completo: ingesta Python/psycopg2, star schema en dbt (staging + marts, 52 tests), y dashboard Streamlit con 4 vistas analíticas desplegado en Streamlit Cloud.
Stakeholders
Sistemas y fuentes
Preguntas de negocio que responde
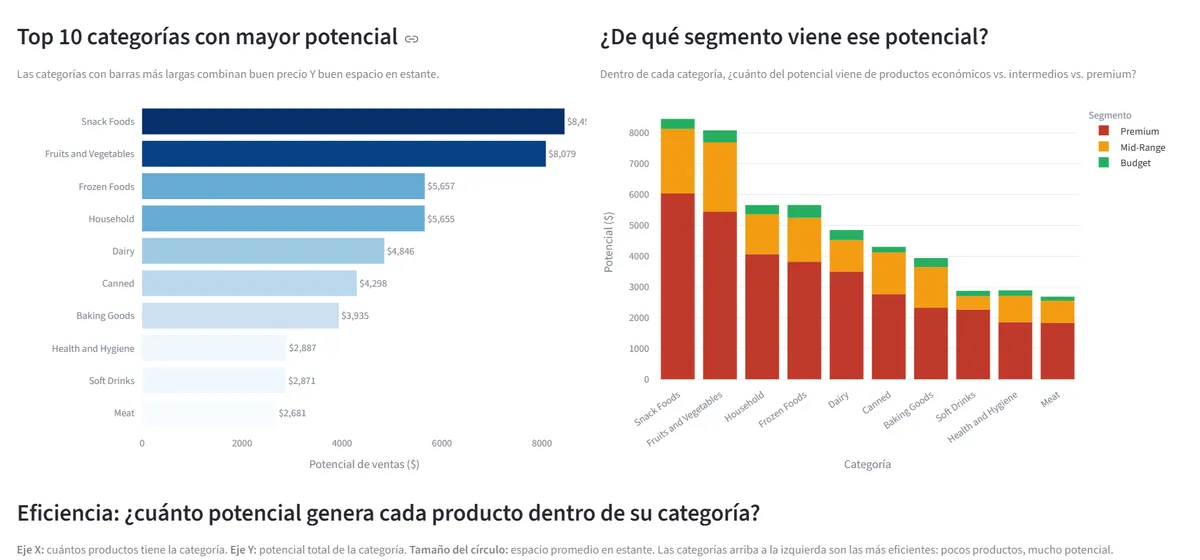
- ¿Qué categorías dominan el espacio en góndola y está eso alineado con su precio?
- ¿Cuál tipo de tienda tiene mayor potencial y amplitud de catálogo?
- ¿Qué segmento de precio concentra el mayor potencial de ingreso?
- ¿Dónde conviene expandir catálogo — mayor potencial con menos SKUs?
Tecnologías
El pivote analítico
El dataset de Blinkit en Kaggle se usa comúnmente para análisis de ventas. Al cargarlo, la columna item_outlet_sales no existía — el archivo era el test set de la competición. En lugar de cambiar el dataset, reformulé la pregunta hacia posicionamiento de catálogo: qué productos reciben visibilidad en el estante, si eso es proporcional a su precio, y qué formatos de tienda encajan mejor con cada segmento. Eso produjo la métrica clave: weighted_revenue_potential = item_mrp × item_shelf_fraction.
Hallazgos principales
- Los productos Mid-Range concentran el mayor potencial de ingreso aunque los Budget los superan en cantidad — el catálogo optimiza volumen, no margen.
- El espacio en góndola y el precio no están correlacionados: productos económicos ocupan más estante que premium, señal de un planograma desalineado.
- Las tiendas Supermarket Type 1 tienen el mayor potencial individual y la mayor amplitud de catálogo — el formato ideal para lanzar productos premium.
Lo que aprendí
- dbt obliga a pensar en capas. Separar staging (renombrar y castear) de marts (lógica de negocio) hace las transformaciones legibles y testeables de forma independiente.
- Los bulk inserts no son opcionales.
execute_valuescargó 5,681 filas en 5 segundos;executemanyhabría tardado 4 minutos. - El deploy en la nube expone lo que el testing local oculta. Encoding de archivos, resolución de hostnames y secrets son invisibles en local — se vuelven bloqueadores en el primer deploy real.
¿Qué te pareció este proyecto?
Si tienes preguntas sobre cómo lo hice o quieres charlar sobre datos, escríbeme.